Spurred by a thread on comp.os.research, I've been reading up on the Synthesis OS design.
Wiki page about Synthesis
The original thesis
This looks like good work, insipring for ARGON; with HYDROGEN explicitly exposing runtime code generation primitives, like any good FORTH system, and the CHROME metaprogramming stuff is based around run time code generation.
I'd hoped to look at how to optimise the system using runtime generation for common stuff - but I expected to have to experiment later; luckily, this fine fellow has blazed a trail for me!
However, I can't help but feel this is more of a programming language issue than an operating systems issue. The author has written an OS in assembly language, and implemented much of it by generating specialised code on the fly rather than jumping to the general code that then has to analyse its dynamic context every time it's executed to decide which control path to take, and having to load data indirectly rather than having it as an immedate value. Surely this stuff should be generalised into a way of optimising all code, rather than just being used in an operating system? I don't see the fundamental technique as being particularly bound to operating systems - lots of applications could benefit from it.
For ARGON, I'd like to use the metaprogramming facilities I've already planned for CHROME to build a toolkit that makes runtime specialisation optimisation easier. Maybe even look into making it happen automatically, although I suspect that the tradeoff involved may require human intervention at heart. A lot of the benefits could be had anyway by just compiling the code in a custom environment containing the constants, which will be constant-propogated and constant-folded and the used as immediate values - but I think those cunning executable data structures need more thinking about...
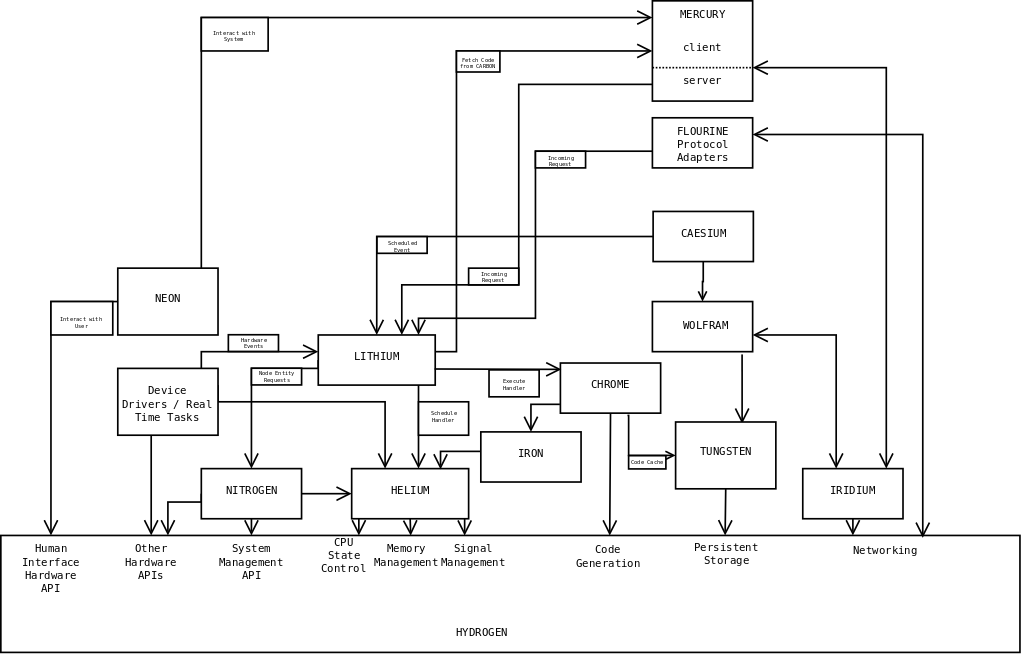
Since I'm always rethinking parts of it faster than I can write them up, ARGON lurks to a great extent inside my own head, with the Web site lagging behind a little. This just helps to make it all the more confusing for interested folks, so I've bitten the bullet and produced a shoddy diagram showing how all the services can fit together on a single running node.
http://www.argon.org.uk/argon-node.png.
Here, we see how the HYDROGEN hardware abstraction layer is used by various components to support WOLFRAM, for in-cluster management of shared state; MERCURY, for inter-cluster and in-cluster communication and FLUORINE for interoperability with other network protocols. These act as interfaces to the entity handler user code - your application - invoking your entities to handle incoming network requests, and providing an API for your code to make outgoing network requests.
I've shown how real-time user tasks will be executed by the HELIUM scheduler in response to timers or incoming signals, and how they interact with local hardware to perform their work.
And I've shown how the NEON user interface subsystem uses the human interface hardware APIs provided by HYDROGEN to proxy between the user and the CARBON directory (for browsing) and MERCURY to then interact with entities to request that they provide code for a user interface front end, which is then executed locally by CHROME in order to provide a responsive user experience for accessing remote resources.
Hopefully, this will make my rantings make a lot more sense to people...
IRON schemas and the CHROME type system are
intertwined... more accurately, I'd say the latter was a superset of
the former.
Let me give a few examples of my requirements for the system.
Read more »
I thought I'd like to discuss the design decisions behind the rather brief description of the "security levels" mentioned on the MERCURY page. Don't worry, you don't need to go and read it first - I'll duplicate everything in this post.
To summarise, my design requirement was to implement a cryptograhic architecture for both communications and storage of sensitive data, which allows for:
- Both parties in a communication may have differing security requirements; the maximum of both need to be met
- Security levels need to be specified in a way that is future proof; eg, DES would have been unbreakable in World War II, but nowadays it should only be considered suitable for relatively unimportant data
- Physical communications links may have a certain element of external protection, rendering encryption an unnecessary burden; a cluster of servers locked in a highly screened server room together should be able to communicate sensitive data between each other in the clear, or with a fast lightweight encryption algorithm - after all, an assailant in the room with them could easily interfere with the machines themselves to get them to divulge their keys. However, the same information being shared across the public Internet would need heavy encryption, or be banned altogether.
Communications links and data storage devices might have a maximum security level of information they can be trusted to at all, no matter how heavily encrypted it is, because any crypto algorithm is potentially breakable.
Read more »
I came across the original paper on Lottery Scheduling.
What was all the fuss about? All it boils down to is using a weighting assigned to each process to divide time between CPU-bound processes at the same priority level. Back when I was a kid and wrote my first preemptive multitasking kernel, that's what I did, because being a lame MS-DOS programmer I hadn't thought of blocked processes being removed from the run queue, and I thought that 'priority' must be such a weighting.
Anyway, it got me thinking. Lottery scheduling is fine for long-running non-real-time processes at the same priority. A user running a few background computational tools such as distributed.net and SETI@Home would benefit from being able to choose the balance between the two at will, sure. But for event-driven tasks like a GUI frontend, a classic priority scheme would still win, if people bothered to set the priorities correctly. As it stands, unless they explicitly make a process 'nice', they usually just leave it to the OS to dynamically assign priority based upon the processes' I/O behaviour, using adaptive heuristics that take a while to respond to changes in the behaviour anyway.
And the inefficincies of this approach are often seen when some heavyweight background computation causes your GUI to become unresponsive...
Read more »

{kind=link}